Topic models and community detection in complex networks
Topic models are a popular way to extract information from text data, but its most popular flavours (based on Dirichlet priors, such as LDA) make unreasonable assumptions about the data which severely limit its applicability. Here we explore an alternative way of doing topic modelling, based on stochastic block models (SBM), thus exploiting a mathematical connection with finding community structure in networks.
To briefly illustrate some of the limitations of Dirichlet-based topic modelling, consider the simple multi-modal mixture of three topics shown below on the left. Since the Dirichlet distribution is unimodal, it severely distorts the topics inferred by LDA, as shown in the middle — even thought it is just a prior distribution over a heterogeneous topic mixture. The SBM formulation, on the other hand, can easily accommodate this kind of heterogeneity, since it is based on more general priors (see here, here, and here).
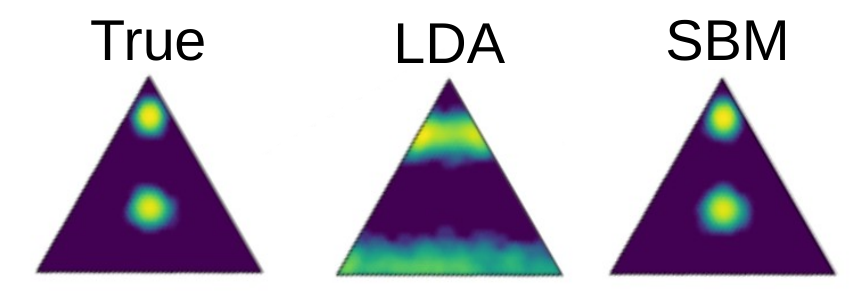
In addition to this, the SBM method is based a nonparametric “symmetric” formulation that allows for the simultaneous hierarchical clustering of documents as well as words. Due to its nonparametric Bayesian nature, the number of topics in each category, as well as the shape and depth of the hierarchy, are automatically determined from the posterior distribution according to the statistical evidence available, avoiding both overfitting and underfitting.
To illustrate the application of the method using real data, we show below an example using wikipedia articles:
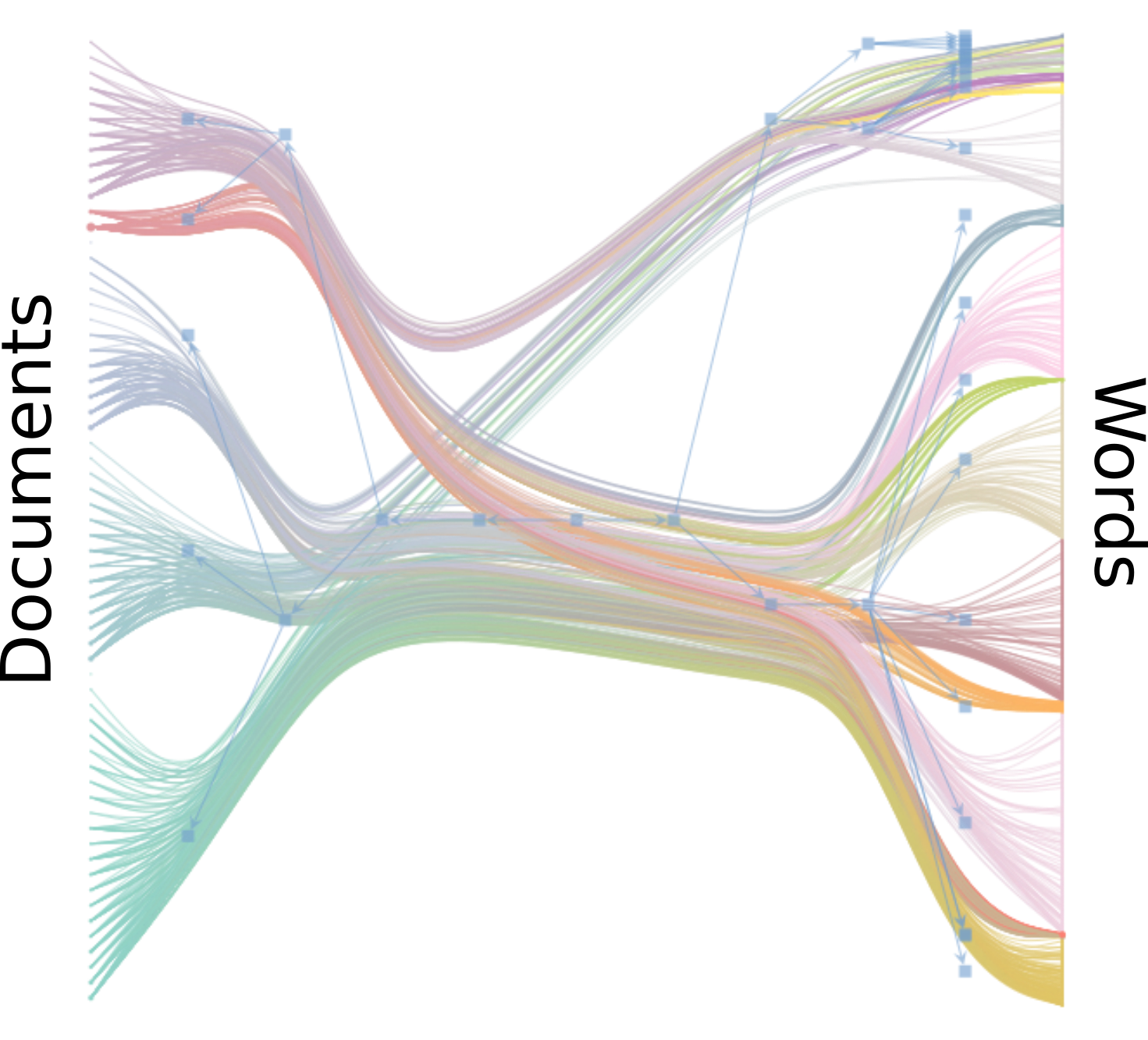 Example: 63 Wikipedia articles related to Physics
Example: 63 Wikipedia articles related to Physics
References:
- A network approach to topic models, Science Advances [link to the paper]
- TopSBM [code]
Science of Science
Evolution of scientific fields
In this project, we used an information-theoretic measure of linguistic similarity (the Jensen-Shannon divergence) to investigate the organization and evolution of scientific fields. An analysis of almost 20 M papers from the past three decades reveals that the linguistic similarity is related but different from experts and citation-based classifications, leading to an improved view on the organization of science. A temporal analysis of the similarity of fields shows that some fields (e.g. computer science) are becoming increasingly central, but that on average the similarity between pairs of disciplines has not changed in the last decades. This suggests that tendencies of convergence (e.g. multi-disciplinarity) and divergence (e.g. specialization) of disciplines are in balance.
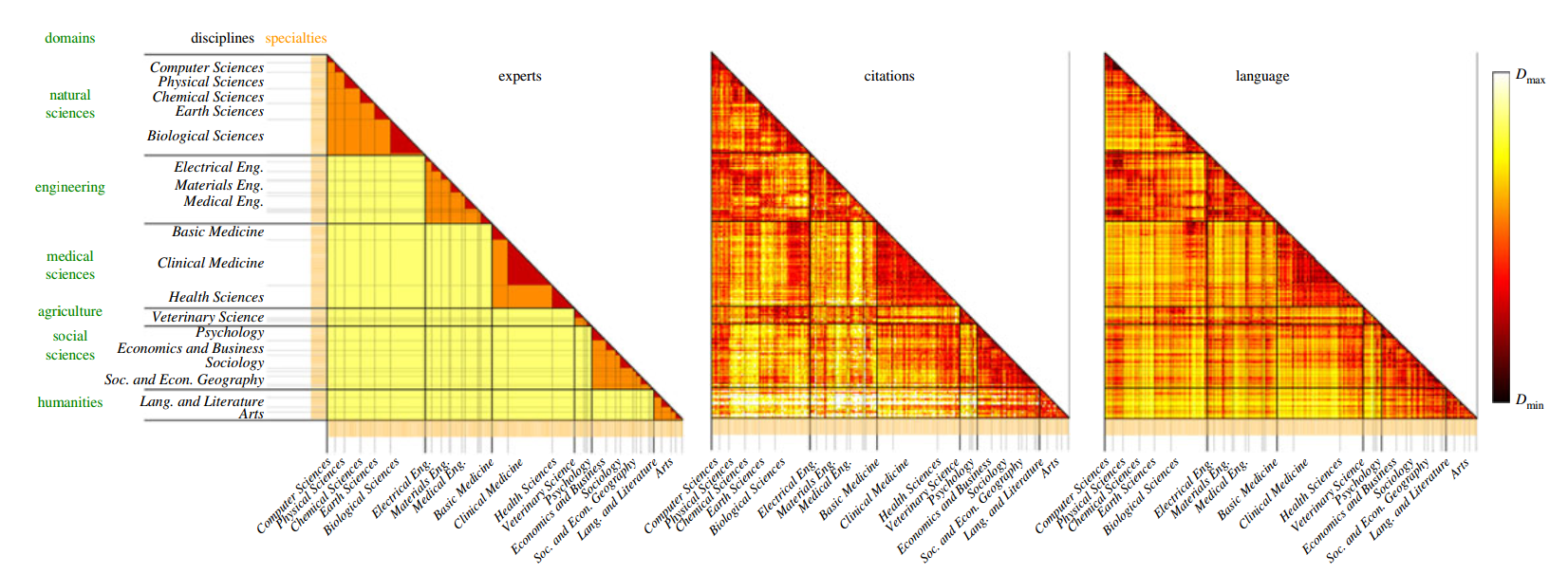 Example: Comparison of dissimilarity between scientific disciplines based on expert classification (left), citations (middle), and language (right). Darker color means fields are more similar.
Example: Comparison of dissimilarity between scientific disciplines based on expert classification (left), citations (middle), and language (right). Darker color means fields are more similar.
References:
- Using text analysis to quantify the similarity and evolution of scientific disciplines, Royal Society Open Science [link to paper]
Related projects:
-
Investigating the reasons for inequality in attention to different research questions. Here we focused on genes of relatively well-defined units of knowledge in biomedical research.
Large-scale investigation of the reasons why potentially important genes are ignored, PLOS Biology [link to paper] -
Investigating where citations occur within the text of a paper.
Large-scale analysis of micro-level citation patterns reveals nuanced selection criteria, Nature Human Behaviour [link to paper]
Statistical Laws in Complex Systems
The availability of large datasets requires an improved view on statistical laws in complex systems, such as Zipf’s law of word frequencies, the Gutenberg-Richter law of earthquake magnitudes, or scale-free degree distribution in networks. Here, we discuss how the statistical analysis of these laws are affected by correlations present in the observations, the typical scenario for data from complex systems. We show how standard maximum-likelihood recipes lead to false rejections of statistical laws in the presence of correlations. We then propose a conservative method (based on shuffling and undersampling the data) to test statistical laws and find that accounting for correlations leads to smaller rejection rates and larger confidence intervals on estimated parameters.
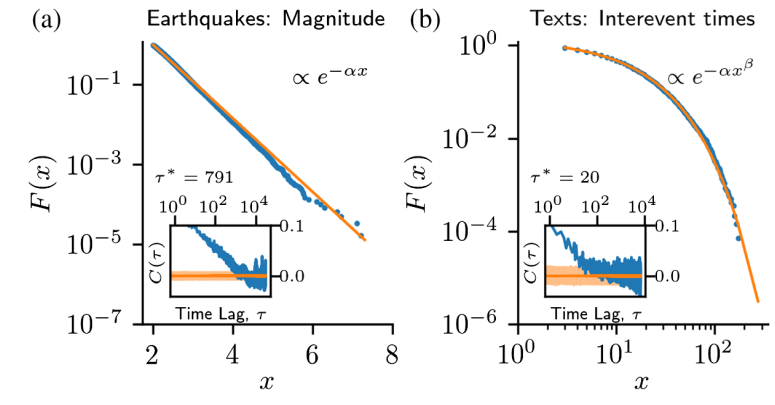
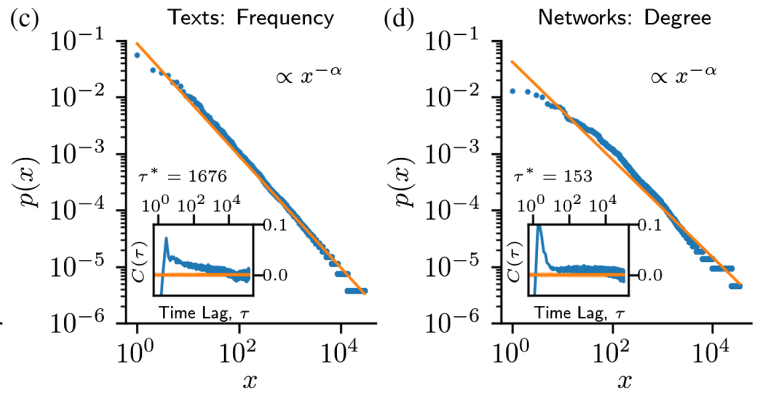
Example of four statistical laws in complex systems together with existence of strong correlations (inset)
References:
- Testing Statistical Laws in Complex Systems, Physical Review Letters [link to paper]
- Review paper on statistical laws in language [link to paper]
Spreading of linguistic innovations
It is well accepted that adoption of innovations are described by S-curves (slow start, accelerating period and slow end). In this project we analyzed how much information on the dynamics of innovation spreading can be obtained from a quantitative description of S-curves. We focused on the adoption of linguistic innovations for which detailed databases of written texts from the last 200 years allow for an unprecedented statistical precision using (Google-ngram containing millions of books from the past 5 centuries). Combining data analysis with simulations of simple models (e.g. the Bass dynamics on complex networks), we identify signatures of endogenous and exogenous factors in the S-curves of adoption. We proposed a measure to quantify the strength of these factors and three different methods to estimate it from S-curves. We obtained cases in which the exogenous factors are dominant (in the adoption of German orthographic reforms and of one irregular verb) and cases in which endogenous factors are dominant (in the adoption of conventions for romanization of Russian names and in the regularization of most studied verbs). These results show that the shape of S-curve is not universal and contains information on the adoption mechanism.
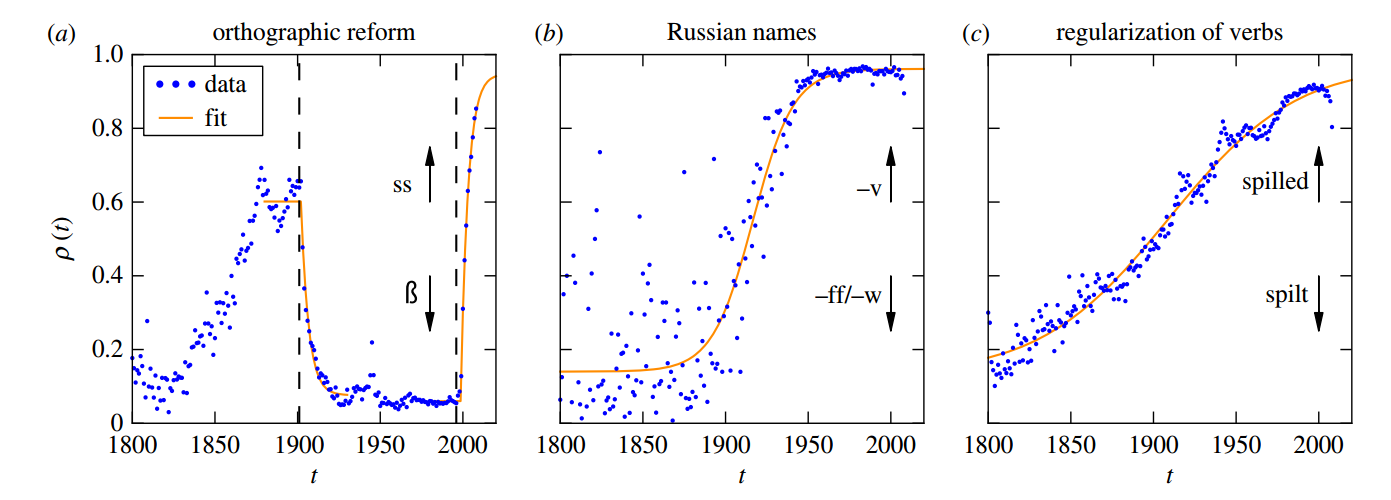 Example of 3 different cases for adoption of linguistic innovations. Orthographic reform in German replacing sharp-s by ss (left), romanization of Russian names (middle), and regularization of past form of English verbs such as spilled vs spilt (right).
Example of 3 different cases for adoption of linguistic innovations. Orthographic reform in German replacing sharp-s by ss (left), romanization of Russian names (middle), and regularization of past form of English verbs such as spilled vs spilt (right).
References:
- Extracting information from S-curves of language change, Journal of the Royal Society Interface [link to paper]