publications
You can also find an up-to-date list of my publications on Google Scholar.
2024
- Architectural styles of curiosity in global Wikipedia mobile app readershipDale Zhou, Shubhankar Patankar, David M. Lydon-Staley, Perry Zurn, Martin Gerlach*, and Dani S. Bassett*Science Advances, 2024
Intrinsically motivated information seeking is an expression of curiosity believed to be central to human nature. However, most curiosity research relies on small, Western convenience samples. Here, we analyze a naturalistic population of 482,760 readers using Wikipedia’s mobile app in 14 languages from 50 countries or territories. By measuring the structure of knowledge networks constructed by readers weaving a thread through articles in Wikipedia, we replicate two styles of curiosity previously identified in laboratory studies: the nomadic “busybody” and the targeted “hunter.” Further, we find evidence for another style—the “dancer”—which was previously predicted by a historico-philosophical examination of texts over two millennia and is characterized by creative modes of knowledge production. We identify associations, globally, between the structure of knowledge networks and population-level indicators of spatial navigation, education, mood, well-being, and inequality. These results advance our understanding of Wikipedia’s global readership and demonstrate how cultural and geographical properties of the digital environment relate to different styles of curiosity.
- Entity Insertion in Multilingual Linked Corpora: The Case of WikipediaTomás Feith, Akhil Arora, Martin Gerlach, Debjit Paul, and Robert WestIn Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024
Links are a fundamental part of information networks, turning isolated pieces of knowledge into a network of information that is much richer than the sum of its parts. However, adding a new link to the network is not trivial: it requires not only the identification of a suitable pair of source and target entities but also the understanding of the content of the source to locate a suitable position for the link in the text. The latter problem has not been addressed effectively, particularly in the absence of text spans in the source that could serve as anchors to insert a link to the target entity. To bridge this gap, we introduce and operationalize the task of entity insertion in information networks. Focusing on the case of Wikipedia, we empirically show that this problem is, both, relevant and challenging for editors. We compile a benchmark dataset in 105 languages and develop a framework for entity insertion called LocEI (Localized Entity Insertion) and its multilingual variant XLocEI. We show that XLocEI outperforms all baseline models (including state-of-the-art prompt-based ranking with LLMs such as GPT-4) and that it can be applied in a zero-shot manner on languages not seen during training with minimal performance drop. These findings are important for applying entity insertion models in practice, e.g., to support editors in adding links across the more than 300 language versions of Wikipedia.
- An Open Multilingual System for Scoring Readability of WikipediaMykola Trokhymovych, Indira Sen, and Martin GerlachIn Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, 2024
With over 60M articles, Wikipedia has become the largest platform for open and freely accessible knowledge. While it has more than 15B monthly visits, its content is believed to be inaccessible to many readers due to the lack of readability of its text. However, previous investigations of the readability of Wikipedia have been restricted to English only, and there are currently no systems supporting the automatic readability assessment of the 300+ languages in Wikipedia. To bridge this gap, we develop a multilingual model to score the readability of Wikipedia articles. To train and evaluate this model, we create a novel multilingual dataset spanning 14 languages, by matching articles from Wikipedia to simplified Wikipedia and online children encyclopedias. We show that our model performs well in a zero-shot scenario, yielding a ranking accuracy of more than 80% across 14 languages and improving upon previous benchmarks. These results demonstrate the applicability of the model at scale for languages in which there is no ground-truth data available for model fine-tuning. Furthermore, we provide the first overview on the state of readability in Wikipedia beyond English.
- Orphan Articles: The Dark Matter of WikipediaAkhil Arora, Robert West, and Martin GerlachIn Proceedings of the Eighteenth International AAAI Conference on Web and Social Media, 2024
With 60M articles in more than 300 language versions, Wikipedia is the largest platform for open and freely accessible knowledge. While the available content has been growing continuously at a rate of around 200K new articles each month, very little attention has been paid to the discoverability of the content. One crucial aspect of discoverability is the integration of hyperlinks into the network so the articles are visible to readers navigating Wikipedia. To understand this phenomenon, we conduct the first systematic study of orphan articles, which are articles without any incoming links from other Wikipedia articles, across 319 different language versions of Wikipedia. We find that a surprisingly large extent of content, roughly 15% (8.8M) of all articles, is de facto invisible to readers navigating Wikipedia, and thus, rightfully term orphan articles as the dark matter of Wikipedia. We also provide causal evidence through a quasi-experiment that adding new incoming links to orphans (de-orphanization) leads to a statistically significant increase in their visibility in terms of the number of pageviews. We further highlight the challenges faced by editors for de-orphanizing articles, demonstrate the need to support them in addressing this issue, and provide potential solutions for developing automated tools based on cross-lingual approaches. Overall, our work not only unravels a key limitation in the link structure of Wikipedia and quantitatively assesses its impact but also provides a new perspective on the challenges of maintenance associated with content creation at scale in Wikipedia.
- Curious Rhythms: Temporal Regularities of Wikipedia ConsumptionTiziano Piccardi, Martin Gerlach, and Robert WestIn Proceedings of the Eighteenth International AAAI Conference on Web and Social Media, 2024
Wikipedia, in its role as the world’s largest encyclopedia, serves a broad range of information needs. Although previous studies have noted that Wikipedia users’ information needs vary throughout the day, there is to date no large-scale, quantitative study of the underlying dynamics. The present paper fills this gap by investigating temporal regularities in daily consumption patterns in a large-scale analysis of billions of timezone-corrected page requests mined from English Wikipedia’s server logs, with the goal of investigating how context and time relate to the kind of information consumed. First, we show that even after removing the global pattern of day-night alternation, the consumption habits of individual articles maintain strong diurnal regularities. Then, we characterize the prototypical shapes of consumption patterns, finding a particularly strong distinction between articles preferred during the evening/night and articles preferred during working hours. Finally, we investigate topical and contextual correlates of Wikipedia articles’ access rhythms, finding that article topic, reader country, and access device (mobile vs. desktop) are all important predictors of daily attention patterns. These findings shed new light on how humans seek information on the Web by focusing on Wikipedia as one of the largest open platforms for knowledge and learning, emphasizing Wikipedia’s role as a rich knowledge base that fulfills information needs spread throughout the day, with implications for understanding information seeking across the globe and for designing appropriate information systems.





2023
- A Large-Scale Characterization of How Readers Browse WikipediaTiziano Piccardi, Martin Gerlach, Akhil Arora, and Robert WestACM Transactions on the Web, 2023
Despite the importance and pervasiveness of Wikipedia as one of the largest platforms for open knowledge, surprisingly little is known about how people navigate its content when seeking information. To bridge this gap, we present the first systematic large-scale analysis of how readers browse Wikipedia. Using billions of page requests from Wikipedia’s server logs, we measure how readers reach articles, how they transition between articles, and how these patterns combine into more complex navigation paths. We find that navigation behavior is characterized by highly diverse structures. Although most navigation paths are shallow, comprising a single pageload, there is much variety, and the depth and shape of paths vary systematically with topic, device type, and time of day. We show that Wikipedia navigation paths commonly mesh with external pages as part of a larger online ecosystem, and we describe how naturally occurring navigation paths are distinct from targeted navigation in lab-based settings. Our results further suggest that navigation is abandoned when readers reach low-quality pages. Taken together, these insights contribute to a more systematic understanding of readers’ information needs and allow for improving their experience on Wikipedia and the Web in general.

2022
- Going Down the Rabbit Hole: Characterizing the Long Tail of Wikipedia Reading SessionsTiziano Piccardi, Martin Gerlach, and Robert WestIn Companion Proceedings of The Web Conference 2022, 2022
"Wiki rabbit holes" are informally defined as navigation paths followed by Wikipedia readers that lead them to long explorations, sometimes involving unexpected articles. Although wiki rabbit holes are a popular concept in Internet culture, our current understanding of their dynamics is based on anecdotal reports only. To bridge this gap, this paper provides a large-scale quantitative characterization of the navigation traces of readers who fell into a wiki rabbit hole. First, we represent user sessions as navigation trees and operationalize the concept of wiki rabbit holes based on the depth of these trees. Then, we characterize rabbit hole sessions in terms of structural patterns, time properties, and topical exploration. We find that article layout influences the structure of rabbit hole sessions and that the fraction of rabbit hole sessions is higher during the night. Moreover, readers are more likely to fall into a rabbit hole starting from articles about entertainment, sports, politics, and history. Finally, we observe that, on average, readers tend to stay focused on one topic by remaining in the semantic neighborhood of the first articles even during rabbit hole sessions. These findings contribute to our understanding of Wikipedia readers’ information needs and user behavior on the Web.
- Wikipedia Reader Navigation: When Synthetic Data Is EnoughAkhil Arora, Martin Gerlach, Tiziano Piccardi, Alberto García-Durán, and Robert WestIn Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, 2022
Every day millions of people read Wikipedia. When navigating the vast space of available topics using embedded hyperlinks, readers follow different trajectories in terms of the sequence of articles. Understanding these navigation patterns is crucial to better serve readers’ needs and address structural biases and knowledge gaps. However, systematic studies of navigation in Wikipedia are limited because of a lack of publicly available data due to the commitment to protect readers’ privacy by not storing or sharing potentially sensitive data. In this paper, we address the question: how well navigation of readers can be approximated by using publicly available resources, most notably the Wikipedia clickstream data? We systematically quantify the difference between real and synthetic navigation sequences generated from the clickstream data, through 6 different experiments across 8 Wikipedia language versions. Overall, we find that these differences are statistically significant but the effect sizes are small often well within 10%. We thus provide quantitative evidence for the utility of the Wikipedia clickstream data as a public resource by showing that it can closely capture reader navigation on Wikipedia, and constitute a sufficient approximation for most practical downstream applications relying on data from readers. More generally, our study provides an example for how clickstream-like data can empower broader research on navigation in other online platforms while protecting users’ privacy.


2021
- Language-agnostic Topic Classification for WikipediaIsaac Johnson, Martin Gerlach, and Diego Sáez-TrumperIn Companion Proceedings of the Web Conference 2021, 2021
A major challenge for many analyses of Wikipedia dynamics—e.g., imbalances in content quality, geographic differences in what content is popular, what types of articles attract more editor discussion—is grouping the very diverse range of Wikipedia articles into coherent, consistent topics. This problem has been addressed using various approaches based on Wikipedia’s category network, WikiProjects, and external taxonomies. However, these approaches have always been limited in their coverage: typically, only a small subset of articles can be classified, or the method cannot be applied across (the more than 300) languages on Wikipedia. In this paper, we propose a language-agnostic approach based on the links in an article for classifying articles into a taxonomy of topics that can be easily applied to (almost) any language and article on Wikipedia. We show that it matches the performance of a language-dependent approach while being simpler and having much greater coverage.
- Multilingual Entity Linking System for Wikipedia with a Machine-in-the-Loop ApproachMartin Gerlach, Marshall Miller, Rita Ho, Kosta Harlan, and Djellel DifallahIn Proceedings of the 30th ACM International Conference on Information & Knowledge Management, 2021
Hyperlinks constitute the backbone of the Web; they enable user navigation, information discovery, content ranking, and many other crucial services on the Internet. In particular, hyperlinks found within Wikipedia allow the readers to navigate from one page to another to expand their knowledge on a given subject of interest or to discover a new one. However, despite Wikipedia editors’ efforts to add and maintain its content, the distribution of links remains sparse in many language editions. This paper introduces a machine-in-the-loop entity linking system that can comply with community guidelines for adding a link and aims at increasing link coverage in new pages and wiki-projects with low resources. To tackle these challenges, we build a context- and language-agnostic entity linking model that combines data collected from millions of anchors found across wiki-projects, as well as billions of users’ reading sessions. We develop an interactive recommendation interface that proposes candidate links to editors who can confirm, reject, or adapt the recommendation with the overall aim of providing a more accessible editing experience for newcomers through structured tasks. Our system’s design choices were made in collaboration with members of several language communities. When the system is implemented as part of Wikipedia, its usage by volunteer editors will help us build a continuous evaluation dataset with active feedback. Our experimental results show that our link recommender can achieve a precision of 74-90% while ensuring a recall of 30-66% across 6 languages covering different sizes, continents, and families.
- Multilayer networks for text analysis with multiple data typesCharles C Hyland, Yuanming Tao, Lamiae Azizi, Martin Gerlach, Tiago P Peixoto, and Eduardo G AltmannEPJ Data Science, 2021
We are interested in the widespread problem of clustering documents and finding topics in large collections of written documents in the presence of metadata and hyperlinks. To tackle the challenge of accounting for these different types of datasets, we propose a novel framework based on Multilayer Networks and Stochastic Block Models. The main innovation of our approach over other techniques is that it applies the same non-parametric probabilistic framework to the different sources of datasets simultaneously. The key difference to other multilayer complex networks is the strong unbalance between the layers, with the average degree of different node types scaling differently with system size. We show that the latter observation is due to generic properties of text, such as Heaps’ law, and strongly affects the inference of communities. We present and discuss the performance of our method in different datasets (hundreds of Wikipedia documents, thousands of scientific papers, and thousands of E-mails) showing that taking into account multiple types of information provides a more nuanced view on topic- and document-clusters and increases the ability to predict missing links.



2020
- Preprint
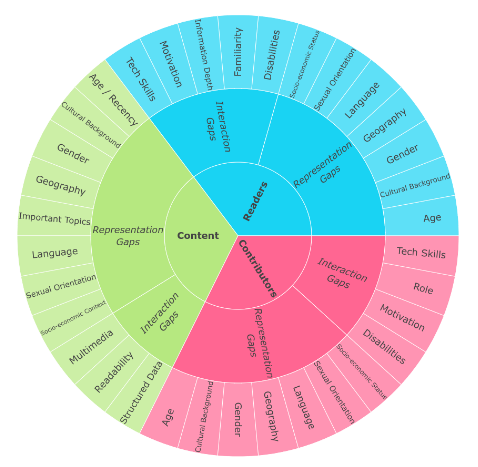 A Taxonomy of Knowledge Gaps for Wikimedia Projects (Second Draft)Miriam Redi, Martin Gerlach, Isaac Johnson, Jonathan Morgan, and Leila ZiaUnpublished, 2020
A Taxonomy of Knowledge Gaps for Wikimedia Projects (Second Draft)Miriam Redi, Martin Gerlach, Isaac Johnson, Jonathan Morgan, and Leila ZiaUnpublished, 2020In January 2019, prompted by the Wikimedia Movement’s 2030 strategic direction, the Research team at the Wikimedia Foundation identified the need to develop a knowledge gaps index – a composite index to support the decision makers across the Wikimedia movement by providing: a framework to encourage structured and targeted brainstorming discussions; data on the state of the knowledge gaps across the Wikimedia projects that can inform decision making and assist with measuring the long term impact of large scale initiatives in the Movement. After its first release in July 2020, the Research team has developed the second complete draft of a taxonomy of knowledge gaps for the Wikimedia projects, as the first step towards building the knowledge gap index. We studied more than 250 references by scholars, researchers, practitioners, community members and affiliates – exposing evidence of knowledge gaps in readership, contributorship, and content of Wikimedia projects. We elaborated the findings and compiled the taxonomy of knowledge gaps in this paper, where we describe, group and classify knowledge gaps into a structured framework. The taxonomy that you will learn more about in the rest of this work will serve as a basis to operationalize and quantify knowledge equity, one of the two 2030 strategic directions, through the knowledge gaps index.
- Preprint
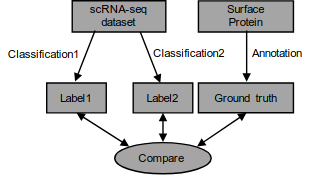 Information-theory-based benchmarking and feature selection algorithm improve cell type annotation and reproducibility of single cell RNA-seq data analysis pipelinesZiyou Ren, Martin Gerlach, Hanyu Shi, G R Scott Budinger, and Luís A Nunes AmaralUnpublished, 2020
Information-theory-based benchmarking and feature selection algorithm improve cell type annotation and reproducibility of single cell RNA-seq data analysis pipelinesZiyou Ren, Martin Gerlach, Hanyu Shi, G R Scott Budinger, and Luís A Nunes AmaralUnpublished, 2020Single cell RNA sequencing (scRNA-seq) data are now routinely generated in experimental practice because of their promise to enable the quantitative study of biological processes at the single cell level. However, cell type and cell state annotations remain an important computational challenge in analyzing scRNA-seq data. Here, we report on the development of a benchmark dataset where reference annotations are generated independently from transcriptomic measurements. We used this benchmark to systematically investigate the impact on labelling accuracy of different approaches to feature selection, of different clustering algorithms, and of different sets of parameter values. We show that an approach grounded on information theory can provide a general, reliable, and accurate process for discarding uninformative features and to optimize cluster resolution in single cell RNA-seq data analysis. ### Competing Interest Statement The authors have declared no competing interest.
- A Standardized Project Gutenberg Corpus for Statistical Analysis of Natural Language and Quantitative LinguisticsMartin Gerlach, and Francesc Font-ClosEntropy, 2020
The use of Project Gutenberg (PG) as a text corpus has been extremely popular in statistical analysis of language for more than 25 years. However, in contrast to other major linguistic datasets of similar importance, no consensual full version of PG exists to date. In fact, most PG studies so far either consider only a small number of manually selected books, leading to potential biased subsets, or employ vastly different pre-processing strategies (often specified in insufficient details), raising concerns regarding the reproducibility of published results. In order to address these shortcomings, here we present the Standardized Project Gutenberg Corpus (SPGC), an open science approach to a curated version of the complete PG data containing more than 50,000 books and more than 3 × 10 9 word-tokens. Using different sources of annotated metadata, we not only provide a broad characterization of the content of PG, but also show different examples highlighting the potential of SPGC for investigating language variability across time, subjects, and authors. We publish our methodology in detail, the code to download and process the data, as well as the obtained corpus itself on three different levels of granularity (raw text, timeseries of word tokens, and counts of words). In this way, we provide a reproducible, pre-processed, full-size version of Project Gutenberg as a new scientific resource for corpus linguistics, natural language processing, and information retrieval.



2019
- A new evaluation framework for topic modeling algorithms based on synthetic corporaHanyu Shi*, Martin Gerlach*, Isabel Diersen, Doug Downey, and Luis AmaralIn Proceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics, 2019
Topic models are in widespread use in natural language processing and beyond. Here, we propose a new framework for the evaluation of topic modeling algorithms based on synthetic corpora containing an unambiguously defined ground truth topic structure. The major innovation of our approach is the ability to quantify the agreement between the planted and inferred topic structures by comparing the assigned topic labels at the level of the tokens. In experiments, our approach yields novel insights about the relative strengths of topic models as corpus characteristics vary, and the first evidence of an “undetectable phase” for topic models when the planted structure is weak. We also establish the practical relevance of the insights gained for synthetic corpora by predicting the performance of topic modeling algorithms in classification tasks in real-world corpora.
- Testing Statistical Laws in Complex SystemsMartin Gerlach, and Eduardo G AltmannPhysical Review Letters, 2019
The availability of large datasets requires an improved view on statistical laws in complex systems, such as Zipf’s law of word frequencies, the Gutenberg-Richter law of earthquake magnitudes, or scale-free degree distribution in networks. In this Letter, we discuss how the statistical analysis of these laws are affected by correlations present in the observations, the typical scenario for data from complex systems. We first show how standard maximum-likelihood recipes lead to false rejections of statistical laws in the presence of correlations. We then propose a conservative method (based on shuffling and undersampling the data) to test statistical laws and find that accounting for correlations leads to smaller rejection rates and larger confidence intervals on estimated parameters.
- Large-scale analysis of micro-level citation patterns reveals nuanced selection criteriaJulia Poncela-Casasnovas, Martin Gerlach, Nathan Aguirre, and Luís A N AmaralNature Human Behaviour, 2019
The analysis of citations to scientific publications has become a tool that is used in the evaluation of a researcher’s work; especially in the face of an ever-increasing production volume1-6. Despite the acknowledged shortcomings of citation analysis and the ongoing debate on the meaning of citations7,8, citations are still primarily viewed as endorsements and as indicators of the influence of the cited reference, regardless of the context of the citation. However, only recently has attention been given to the connection between contextual information and the success of citing and cited papers, primarily because of the lack of extensive databases that cover both types of metadata. Here we address this issue by studying the usage of citations throughout the full text of 156,558 articles published by the Public Library of Science (PLoS), and by tracing their bibliometric history from among 60 million records obtained from the Web of Science. We find universal patterns of variation in the usage of citations across paper sections11. Notably, we find differences in microlevel citation patterns that were dependent on the ultimate impact of the citing paper itself; publications from high-impact groups tend to cite younger references, as well as more very young and better-cited references. Our study provides a quantitative approach to addressing the long-standing issue that not all citations count the same.
- A universal information theoretic approach to the identification of stopwordsMartin Gerlach, Hanyu Shi, and Luís A Nunes AmaralNature Machine Intelligence, 2019
One of the most widely used approaches in natural language processing and information retrieval is the so-called bag-of-words model. A common component of such methods is the removal of uninformative words, commonly referred to as stopwords. Currently, most practitioners use manually curated stopword lists. This approach is problematic because it cannot be readily generalized across knowledge domains or languages. As a result of the difficulty in rigorously defining stopwords, there have been few systematic studies on the effect of stopword removal on algorithm performance, which is reflected in the ongoing debate on whether to keep or remove stopwords. Here we address this challenge by formulating an information theoretic framework that automatically identifies uninformative words in a corpus. We show that our framework not only outperforms other stopword heuristics, but also allows for a substantial reduction of document size in applications of topic modelling. Our findings can be readily generalized to other bag-of-words-type approaches beyond language such as in the statistical analysis of transcriptomics, audio or image corpora.
- Preprint
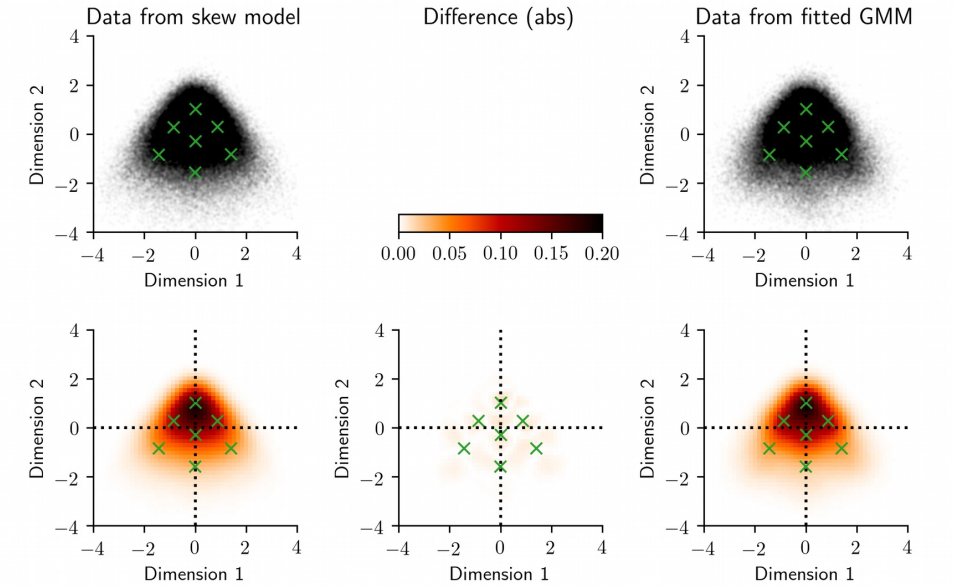 Reply to Katahira et al. “Distribution of personality: Types or skewness?”Martin Gerlach, William Revelle, and Luis A N AmaralUnpublished, 2019
Reply to Katahira et al. “Distribution of personality: Types or skewness?”Martin Gerlach, William Revelle, and Luis A N AmaralUnpublished, 2019Katahira et al. investigated the potential impact of skewness in the marginal distributions of personality trait on the findings reported by us in Gerlach et al. We concur with Katahira et al.’s finding in synthetic 2-dimensional data that there exists a mechanism by which skewness can induce detection of “meaningful clusters” using our proposed methodology. Here, we argue that skewness cannot fully account for the deviations from the null model for the data studied in our original study.






2018
- Large-scale investigation of the reasons why potentially important genes are ignoredThomas Stoeger, Martin Gerlach, Richard I Morimoto, and Luís A Nunes AmaralPLoS Biology, 2018
Biomedical research has been previously reported to primarily focus on a minority of all known genes. Here, we demonstrate that these differences in attention can be explained, to a large extent, exclusively from a small set of identifiable chemical, physical, and biological properties of genes. Together with knowledge about homologous genes from model organisms, these features allow us to accurately predict the number of publications on individual human genes, the year of their first report, the levels of funding awarded by the National Institutes of Health (NIH), and the development of drugs against disease-associated genes. By explicitly identifying the reasons for gene-specific bias and performing a meta-analysis of existing computational and experimental knowledge bases, we describe gene-specific strategies for the identification of important but hitherto ignored genes that can open novel directions for future investigation.
- Reply to "Far away from the lamppost"Thomas Stoeger, Martin Gerlach, Richard I Morimoto, and Luís A Nunes AmaralPLoS Biology, 2018
In this Formal Comment, the authors of the recent publication "Large-scale investigation of the reasons why potentially important genes are ignored" maintain that it can be read as an opportunity to explore the unknown.
- A network approach to topic modelsMartin Gerlach, Tiago P Peixoto, and Eduardo G AltmannScience Advances, 2018
One of the main computational and scientific challenges in the modern age is to extract useful information from unstructured texts. Topic models are one popular machine-learning approach that infers the latent topical structure of a collection of documents. Despite their success-particularly of the most widely used variant called latent Dirichlet allocation (LDA)-and numerous applications in sociology, history, and linguistics, topic models are known to suffer from severe conceptual and practical problems, for example, a lack of justification for the Bayesian priors, discrepancies with statistical properties of real texts, and the inability to properly choose the number of topics. We obtain a fresh view of the problem of identifying topical structures by relating it to the problem of finding communities in complex networks. We achieve this by representing text corpora as bipartite networks of documents and words. By adapting existing community-detection methods (using a stochastic block model (SBM) with nonparametric priors), we obtain a more versatile and principled framework for topic modeling (for example, it automatically detects the number of topics and hierarchically clusters both the words and documents). The analysis of artificial and real corpora demonstrates that our SBM approach leads to better topic models than LDA in terms of statistical model selection. Our work shows how to formally relate methods from community detection and topic modeling, opening the possibility of cross-fertilization between these two fields.
- A robust data-driven approach identifies four personality types across four large data setsMartin Gerlach, Beatrice Farb, William Revelle, and Luís A Nunes AmaralNature Human Behaviour, 2018
Understanding human personality has been a focus for philosophers and scientists for millennia1. It is now widely accepted that there are about five major personality domains that describe the personality profile of an individual2,3. In contrast to personality traits, the existence of personality types remains extremely controversial4. Despite the various purported personality types described in the literature, small sample sizes and the lack of reproducibility across data sets and methods have led to inconclusive results about personality types5,6. Here we develop an alternative approach to the identification of personality types, which we apply to four large data sets comprising more than 1.5 million participants. We find robust evidence for at least four distinct personality types, extending and refining previously suggested typologies. We show that these types appear as a small subset of a much more numerous set of spurious solutions in typical clustering approaches, highlighting principal limitations in the blind application of unsupervised machine learning methods to the analysis of big data.
- Using text analysis to quantify the similarity and evolution of scientific disciplinesLaércio Dias, Martin Gerlach, Joachim Scharloth, and Eduardo G AltmannRoyal Society Open Science, 2018
We use an information-theoretic measure of linguistic similarity to investigate the organization and evolution of scientific fields. An analysis of almost 20 M papers from the past three decades reveals that the linguistic similarity is related but different from experts and citation-based classifications, leading to an improved view on the organization of science. A temporal analysis of the similarity of fields shows that some fields (e.g. computer science) are becoming increasingly central, but that on average the similarity between pairs of disciplines has not changed in the last decades. This suggests that tendencies of convergence (e.g. multi-disciplinarity) and divergence (e.g. specialization) of disciplines are in balance.




2017
- Generalized entropies and the similarity of textsEduardo G Altmann, Laércio Dias, and Martin GerlachJournal of Statistical Mechanics: Theory and Experiment, 2017
We show how generalized Gibbs-Shannon entropies can provide new insights on the statistical properties of texts. The universal distribution of word frequencies (Zipf’s law) implies that the generalized entropies, computed at the word level, are dominated by words in a specific range of frequencies. Here we show that this is the case not only for the generalized entropies but also for the generalized (Jensen-Shannon) divergences, used to compute the similarity between different texts. This finding allows us to identify the contribution of specific words (and word frequencies) for the different generalized entropies and also to estimate the size of the databases needed to obtain a reliable estimation of the divergences. We test our results in large databases of books (from the Google n-gram database) and scientific papers (indexed by Web of Science).

2016
- Thesis
 Universality and variability in the statistics of data with fat-tailed distributions: the case of word frequencies in natural languagesMartin GerlachDoctoral Thesis (Dr. rer. nat.). presented to the Physics Department of Dresden University of Technology; produced at the Max Planck Institute for the Physics of Complex Systems , 2016
Universality and variability in the statistics of data with fat-tailed distributions: the case of word frequencies in natural languagesMartin GerlachDoctoral Thesis (Dr. rer. nat.). presented to the Physics Department of Dresden University of Technology; produced at the Max Planck Institute for the Physics of Complex Systems , 2016Natural language is a remarkable example of a complex dynamical system which combines variation and universal structure emerging from the interaction of millions of individuals. Understanding statistical properties of texts is not only crucial in applications of information retrieval and natural language processing, e.g. search engines, but also allow deeper insights into the organization of knowledge in the form of written text. In this thesis, we investigate the statistical and dynamical processes underlying the co-existence of universality and variability in word statistics. We combine a careful statistical analysis of large empirical databases on language usage with analytical and numerical studies of stochastic models. We find that the fat-tailed distribution of word frequencies is best described by a generalized Zipf’s law characterized by two scaling regimes, in which the values of the parameters are extremely robust with respect to time as well as the type and the size of the database under consideration depending only on the particular language. We provide an interpretation of the two regimes in terms of a distinction of words into a finite core vocabulary and a (virtually) infinite noncore vocabulary. Proposing a simple generative process of language usage, we can establish the connection to the problem of the vocabulary growth, i.e. how the number of different words scale with the database size, from which we obtain a unified perspective on different universal scaling laws simultaneously appearing in the statistics of natural language. On the one hand, our stochastic model accurately predicts the expected number of different items as measured in empirical data spanning hundreds of years and 9 orders of magnitude in size showing that the supposed vocabulary growth over time is mainly driven by database size and not by a change in vocabulary richness. On the other hand, analysis of the variation around the expected size of the vocabulary shows anomalous fluctuation scaling, i.e. the vocabulary is a nonself-averaging quantity, and therefore, fluctuations are much larger than expected. We derive how this results from topical variations in a collection of texts coming from different authors, disciplines, or times manifest in the form of correlations of frequencies of different words due to their semantic relation. We explore the consequences of topical variation in applications to language change and topic models emphasizing the difficulties (and presenting possible solutions) due to the fact that the statistics of word frequencies are characterized by a fat-tailed distribution. First, we propose an information-theoretic measure based on the Shannon-Gibbs entropy and suitable generalizations quantifying the similarity between different texts which allows us to determine how fast the vocabulary of a language changes over time. Second, we combine topic models from machine learning with concepts from community detection in complex networks in order to infer large-scale (mesoscopic) structures in a collection of texts. Finally, we study language change of individual words on historical time scales, i.e. how a linguistic innovation spreads through a community of speakers, providing a framework to quantitatively combine microscopic models of language change with empirical data that is only available on a macroscopic level (i.e. averaged over the population of speakers).
- Similarity of Symbol Frequency Distributions with Heavy TailsMartin Gerlach, Francesc Font-Clos, and Eduardo G AltmannPhysical Review X, 2016
Quantifying the similarity between symbolic sequences is a traditional problem in Information Theory which requires comparing the frequencies of symbols in different sequences. In numerous modern applications, ranging from DNA over music to texts, the distribution of symbol frequencies is characterized by heavy-tailed distributions (e.g., Zipf’s law). The large number of low-frequency symbols in these distributions poses major difficulties to the estimation of the similarity between sequences, e.g., they hinder an accurate finite-size estimation of entropies. Here we show how the accuracy of estimations depend on the sample size~\N not only for the Shannon entropy \(}alpha=1) and its corresponding similarity measures (e.g., the Jensen-Shanon divergence) but also for measures based on the generalized entropy of order {}alpha\. For small {}alphaś, including {}alpha=1 the bias and fluctuations in the estimations decay slower than the \1/N decay observed in short-tailed distributions. For {}alpha larger than a critical value {}alpha^*}leq 2 the \1/N\-scaling is recovered. We show the practical significance of our results by quantifying the evolution of the English language over the last two centuries using a complete {}alpha\-spectrum of measures. We find that frequent words change more slowly than less frequent words and that {}alpha=2 provides the most robust measure to quantify language change.
- BookChapter
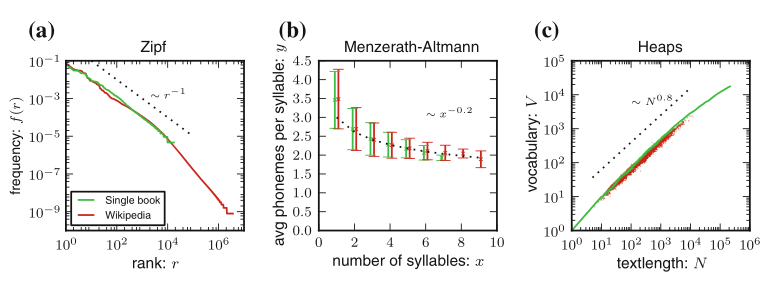 Statistical laws in linguisticsEduardo G Altmann, and Martin GerlachIn Creativity and Universality in Language, 2016
Statistical laws in linguisticsEduardo G Altmann, and Martin GerlachIn Creativity and Universality in Language, 2016Zipf’s law is just one out of many universal laws proposed to describe statistical regularities in language. Here we review and critically discuss how these laws can be statistically interpreted, fitted, and tested (falsified). The modern availability of large databases of written text allows for tests with an unprecedent statistical accuracy and also a characterization of the fluctuations around the typical behavior. We find that fluctuations are usually much larger than expected based on simplifying statistical assumptions (e.g., independence and lack of correlations between observations).These simplifications appear also in usual statistical tests so that the large fluctuations can be erroneously interpreted as a falsification of the law. Instead, here we argue that linguistic laws are only meaningful (falsifiable) if accompanied by a model for which the fluctuations can be computed (e.g., a generative model of the text). The large fluctuations we report show that the constraints imposed by linguistic laws on the creativity process of text generation are not as tight as one could expect.
- Is this scaling nonlinear?Jorge C. Leitão, Jose M. Miotto, Martin Gerlach, and Eduardo G. AltmannRoyal Society Open Science, 2016
One of the most celebrated findings in complex systems in the last decade is that different indexes y (e.g., patents) scale nonlinearly with the population~x of the cities in which they appear, i.e., \y}sim x^}beta, }beta }neq 1\. More recently, the generality of this finding has been questioned in studies using new databases and different definitions of city boundaries. In this paper we investigate the existence of nonlinear scaling using a probabilistic framework in which fluctuations are accounted explicitly. In particular, we show that this allows not only to (a) estimate {}beta and confidence intervals, but also to (b) quantify the evidence in favor of {}beta }neq 1 and (c) test the hypothesis that the observations are compatible with the nonlinear scaling. We employ this framework to compare \5 different models to \15 different datasets and we find that the answers to points (a)-(c) crucially depend on the fluctuations contained in the data, on how they are modeled, and on the fact that the city sizes are heavy-tailed distributed.




2014
- Extracting information from S-curves of language changeFakhteh Ghanbarnejad*, Martin Gerlach*, Jose M Miotto, and Eduardo G AltmannJournal of the Royal Society Interface, 2014
It is well accepted that adoption of innovations are described by S-curves (slow start, accelerating period and slow end). In this paper, we analyse how much information on the dynamics of innovation spreading can be obtained from a quantitative description of S-curves. We focus on the adoption of linguistic innovations for which detailed databases of written texts from the last 200 years allow for an unprecedented statistical precision. Combining data analysis with simulations of simple models (e.g. the Bass dynamics on complex networks), we identify signatures of endogenous and exogenous factors in the S-curves of adoption. We propose a measure to quantify the strength of these factors and three different methods to estimate it from S-curves. We obtain cases in which the exogenous factors are dominant (in the adoption of German orthographic reforms and of one irregular verb) and cases in which endogenous factors are dominant (in the adoption of conventions for romanization of Russian names and in the regularization of most studied verbs). These results show that the shape of S-curve is not universal and contains information on the adoption mechanism.
- Scaling laws and fluctuations in the statistics of word frequenciesMartin Gerlach, and Eduardo G AltmannNew Journal of Physics, 2014
In this paper, we combine statistical analysis of written texts and simple stochastic models to explain the appearance of scaling laws in the statistics of word frequencies. The average vocabulary of an ensemble of fixed-length texts is known to scale sublinearly with the total number of words (Heaps’ law). Analyzing the fluctuations around this average in three large databases (Google-ngram, English Wikipedia, and a collection of scientific articles), we find that the standard deviation scales linearly with the average (Taylorʼs law), in contrast to the prediction of decaying fluctuations obtained using simple sampling arguments. We explain both scaling laws (Heaps’ and Taylor) by modeling the usage of words using a Poisson process with a fat-tailed distribution of word frequencies (Zipfʼs law) and topic-dependent frequencies of individual words (as in topic models). Considering topical variations lead to quenched averages, turn the vocabulary size a non-self-averaging quantity, and explain the empirical observations. For the numerous practical applications relying on estimations of vocabulary size, our results show that uncertainties remain large even for long texts. We show how to account for these uncertainties in measurements of lexical richness of texts with different lengths.


2013
- Stochastic Model for the Vocabulary Growth in Natural LanguagesMartin Gerlach, and Eduardo G AltmannPhysical Review X, 2013
We propose a stochastic model for the number of different words in a given database which incorporates the dependence on the database size and historical changes. The main feature of our model is the existence of two different classes of words: (i) a finite number of core-words which have higher frequency and do not affect the probability of a new word to be used; and (ii) the remaining virtually infinite number of noncore-words which have lower frequency and once used reduce the probability of a new word to be used in the future. Our model relies on a careful analysis of the google-ngram database of books published in the last centuries and its main consequence is the generalization of Zipf’s and Heaps’ law to two scaling regimes. We confirm that these generalizations yield the best simple description of the data among generic descriptive models and that the two free parameters depend only on the language but not on the database. From the point of view of our model the main change on historical time scales is the composition of the specific words included in the finite list of core-words, which we observe to decay exponentially in time with a rate of approximately 30 words per year.

2012
- Kicking electronsMartin Gerlach, Sebastian Wüster, and Jan M RostJournal of Physics B: Atomic, Molecular and Optical Physics, 2012
The concept of dominant interaction Hamiltonians is introduced. It is applied as a test case to classical planar electron–atom scattering. Each trajectory is governed in different time intervals by two variants of a separable approximate Hamiltonian. Switching between them results in exchange of energy between the two electrons. A second mechanism condenses the electron–electron interaction to instants in time and leads to an exchange of energy and angular momentum among the two electrons in the form of kicks. We calculate the approximate and full classical deflection functions and show that the latter can be interpreted in terms of the switching sequences of the approximate one. Finally, we demonstrate that the quantum results agree better with the approximate classical dynamical results than with the full ones.

2011
- Thesis
 Hamiltonians dominanter WechselwirkungMartin GerlachDiploma Thesis (Diplom-Physiker). presented to the Physics Department of Dresden University of Technology; produced at the Max Planck Institute for the Physics of Complex Systems , 2011
Hamiltonians dominanter WechselwirkungMartin GerlachDiploma Thesis (Diplom-Physiker). presented to the Physics Department of Dresden University of Technology; produced at the Max Planck Institute for the Physics of Complex Systems , 2011In this work the non-integrable classical dynamics of the helium atom is approximated by means of separable Hamiltonians in different parts of phase space. This is realized by switching between the Hamiltonians according to the dominant interaction along a classical trajectory. Using the example of electron-impact scattering it is shown that this proves to be a suitable approximation which provides a classification scheme for the trajectories with respect to their characteristic behaviour. The comparison with corresponding quantum calculations shows in addition that the approximated dynamics are in better agreement with the quantum results than the full classical dynamics.
